As technology continues to advance, businesses are collecting and storing more data than ever before. The sheer volume of data being generated has given rise to the need for more sophisticated data management systems. Two popular options for managing big data infrastructure are data warehousing and data lakes.
What is Data Warehousing?
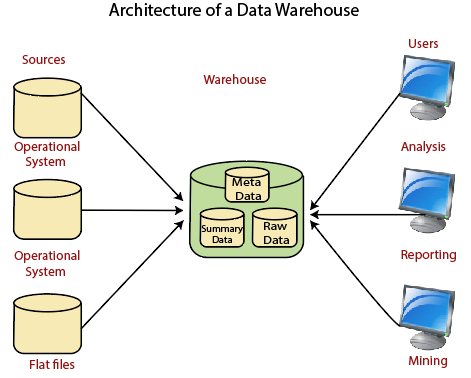
Data warehousing is a method of storing and managing data that has been structured and organized in a way that makes it easy to access and analyze. Data warehouses are typically used for storing historical data and are optimized for read-heavy workloads. They are designed to support complex queries and provide fast access to data for reporting and analysis purposes.
One of the key benefits of data warehousing is that it allows businesses to consolidate data from multiple sources into a single repository, making it easier to analyze and derive insights from the data. Data warehouses are also designed to ensure data quality and consistency, which is important for making informed business decisions.
What is a Data Lake?
A data lake is a more flexible and scalable approach to data storage that allows businesses to store large amounts of raw, unstructured data in its native format. Data lakes are typically used for storing and processing big data, as they can handle a wide variety of data types and sources.
Unlike data warehouses, data lakes do not require data to be structured before it is loaded into the system. This makes it easier for businesses to store and analyze diverse data sets, including text, images, videos, and sensor data.
Key Differences Between Data Warehousing and Data Lakes
Data Structure: Data warehouses store structured data, while data lakes store unstructured data.
Query Performance: Data warehouses are optimized for read-heavy workloads and complex queries, while data lakes are more suitable for ad-hoc queries and exploratory analysis.
Data Quality: Data warehouses ensure data quality and consistency, while data lakes may require additional data cleansing and transformation.
Scalability: Data lakes are more scalable and cost-effective for storing large volumes of data, while data warehouses may require additional hardware and infrastructure to scale.
Best Practices for Managing Big Data Infrastructure
When it comes to managing big data infrastructure, businesses should consider a hybrid approach that combines the strengths of both data warehousing and data lakes. By leveraging the capabilities of both systems, businesses can achieve greater flexibility and scalability in their data management strategy.
Data Integration: Develop a comprehensive data integration strategy to ensure seamless data flow between data warehouses and data lakes.
Data Governance: Implement robust data governance policies to maintain data quality and ensure compliance with regulations.
Data Security: Implement stringent data security measures to protect sensitive data and prevent unauthorized access.
Data Analytics: Utilize advanced analytics tools and techniques to derive valuable insights from the data stored in data warehouses and data lakes.
Conclusion
Managing big data infrastructure is a complex and challenging task, but by leveraging the capabilities of data warehousing and data lakes, businesses can effectively store, manage, and analyze large volumes of data. By following best practices for data integration, governance, security, and analytics, businesses can harness the power of big data to drive innovation and achieve competitive advantage in today’s digital landscape.