Machine learning is at the forefront of technological advancements in the field of data science. It has revolutionized the way businesses make decisions, optimize processes, and create value from their data. One of the key applications of machine learning in data science is predictive modeling and classification, which involves using algorithms to make predictions and classify data based on patterns and relationships.
The Basics of Predictive Modeling
Predictive modeling is a technique used in data science to predict future events or outcomes based on historical data. This can be done by analyzing patterns and relationships in the data and building models that can be used to make predictions. Predictive modeling is widely used in a variety of industries, including finance, healthcare, marketing, and e-commerce, to forecast customer behavior, identify trends, and optimize decision-making processes.
Types of Predictive Modeling Algorithms
There are several types of algorithms used in predictive modeling, including linear regression, decision trees, support vector machines, and neural networks. Each algorithm has its strengths and weaknesses, and the choice of algorithm depends on the complexity of the data and the desired outcome. For example, linear regression is often used for simple relationships between variables, while neural networks are more powerful for modeling complex relationships.
The Role of Machine Learning in Predictive Modeling
Machine learning plays a crucial role in predictive modeling by automating the process of building and refining models. Machine learning algorithms can analyze large datasets and identify patterns and relationships that humans may not be able to detect. This allows businesses to make more accurate predictions and make better decisions based on data-driven insights.
Challenges in Predictive Modeling
While predictive modeling offers many benefits, it also comes with challenges. Some of the common challenges include overfitting, data quality issues, and interpretability of models. Overfitting occurs when a model performs well on the training data but fails to generalize to new, unseen data. Data quality issues, such as missing or inaccurate data, can lead to biased or unreliable predictions. Interpreting complex machine learning models can also be a challenge, as they may not always provide clear explanations for their predictions.
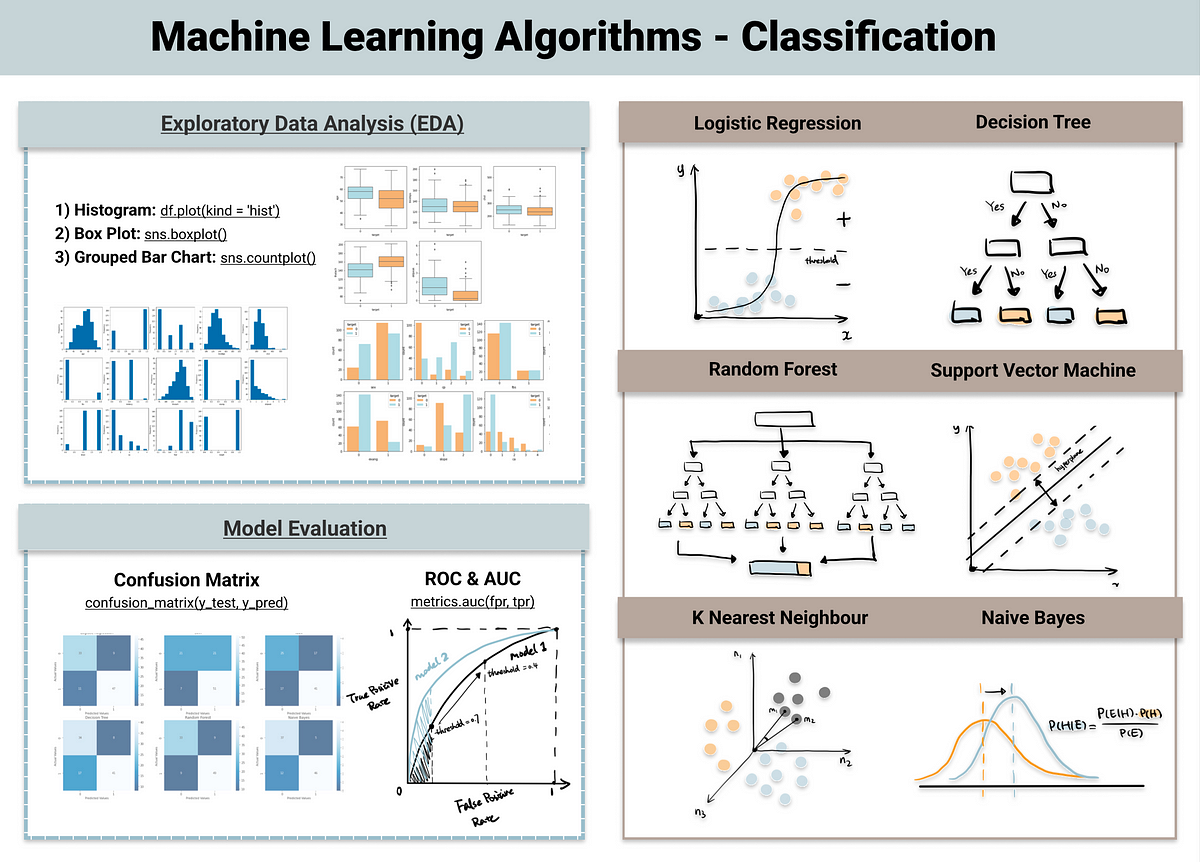
Classification in Data Science
Classification is another important application of machine learning in data science. It involves categorizing data into groups or classes based on their attributes. Classification is used in a variety of tasks, such as spam detection, image recognition, sentiment analysis, and credit scoring. Machine learning algorithms, such as logistic regression, support vector machines, and random forests, are commonly used for classification tasks.
Conclusion
Machine learning has transformed the field of data science by enabling businesses to make more accurate predictions and classify data efficiently. Predictive modeling and classification are powerful techniques that can help businesses uncover valuable insights from their data and make better decisions. By leveraging machine learning algorithms and techniques, businesses can gain a competitive edge and drive innovation in their respective industries.
References
1. James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An Introduction to Statistical Learning: with applications in R. New York: Springer.
2. Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. New York: Springer.